Итак, инструмент администратора — Perfomance Monitor. Для того, чтобы результаты могли быть сохранены, откроем mmc и добавим Perfomance Monitor:
Т.к. дисковая с-ма традиционно является наиболее «узким» местом, начнем с нее. У подключено два диска: SSD и SATA, F: и D: соответственно, для них установим счетчики:
Logical Disk(*)% Disk Time
Logical Disk(*)Avg. Disk Queue Length
Logical Disk(*)Avg. Disk sec/Read
Logical Disk(*)Avg. Disk sec/Write
Logical Disk(*)Current Disk Queue Length
Обратите внимание, % Disk Time и Disk Queue Length это одно и то же значение, с разной формой представления информации (значение «1» Disk Queue Length равно значению «100» % Disk Time).
Очевидно, % Disk Time может быть более 100%. Два аналогичных занчения могут быть использованы для передачи инфы в специфичные с-мы мониторинга, что и будет сделано (в этой статье не будет описано).
Нормы значений из документации:
Logical Disk()Avg. Disk sec/Read & Logical Disk()Avg. Disk sec/Write
1ms to 15ms = Healthy
15ms to 25ms = Warning or Monitor
26ms or greater = Critical, performance will be adversely affected
Disk Queue Length не более 2, или 200% в % Disk Time. Более двух — это уже перегрузка, для хоста виртуализации это критично.
Теперь перейдем к мониторингу оперативной памяти и настроим счетчик
MemoryPages/sec
Нормой для этого параметра являются:
Less than 500 = Healthy
500 — 1000 = Monitor or Caution
Greater than 1000 = Critical, performance will be adversely affected
Официальная документация рекомендует мониторить параметр:
MemoryAvailable Mbytes
..и быть тревогу только тогда, когда свободно менее 5% памяти.
Для Standalone хоста это ок, но если хост является нодой кластера, то нормы значения должны быть определены дизайном кластера.
Мониторинг использования процессора гипервизора отличается от классического метода, и для него используются другие счетчики:
Hyper-V Hypervisor Logical Processor(_Total)% Total Run Time
Опять же, «официальные» рекомендации бить тревогу если загрузка выше 90% ок, но если кластер, то нормы определяются его дизайном.
Hyper-V Hypervisor Virtual Processor(_Total)% Total Run Time
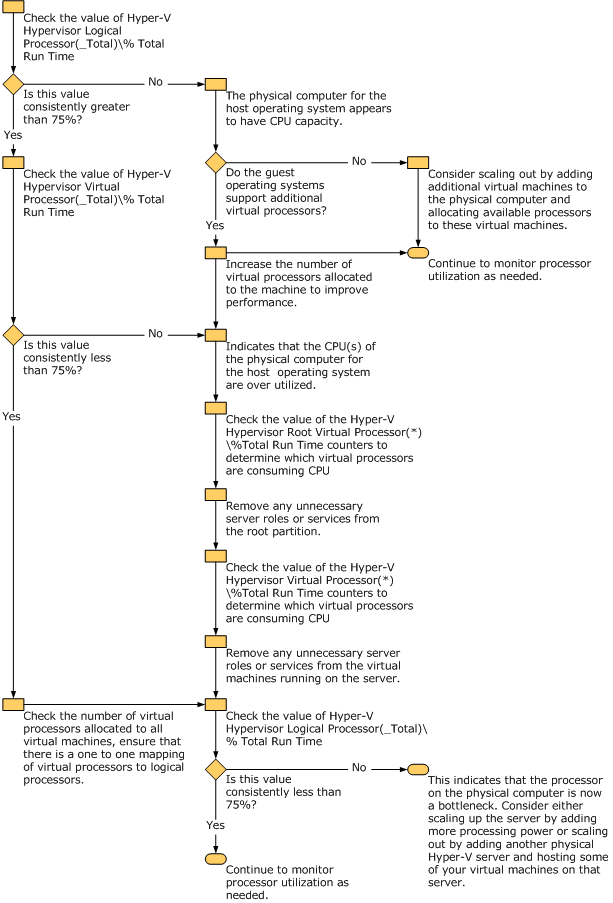
В документации, есть отличная диаграмма, которая показывает процесс траблшутинга процессорной производительности:
Учитывая тот факт, что на момент внедрения виртуализации сеть должна быть в полном порядке, а также факт того что в 2013 году диагностика сети задача, которую может решить практически любой ИТ специалист, я обращу внимание только на такие счетчики как:
Network Interface(*)Bytes Total/sec
Less than 40% of the interface consumed = Healthy
41%-64% of the interface consumed = Monitor or Caution
65-100% of the interface consumed = Critical, performance will be adversely affected
Network Interface(*)Output Queue Length
Если в очереди более 1, это повод обратить внимание, конечно.
Теперь сохраним результаты:
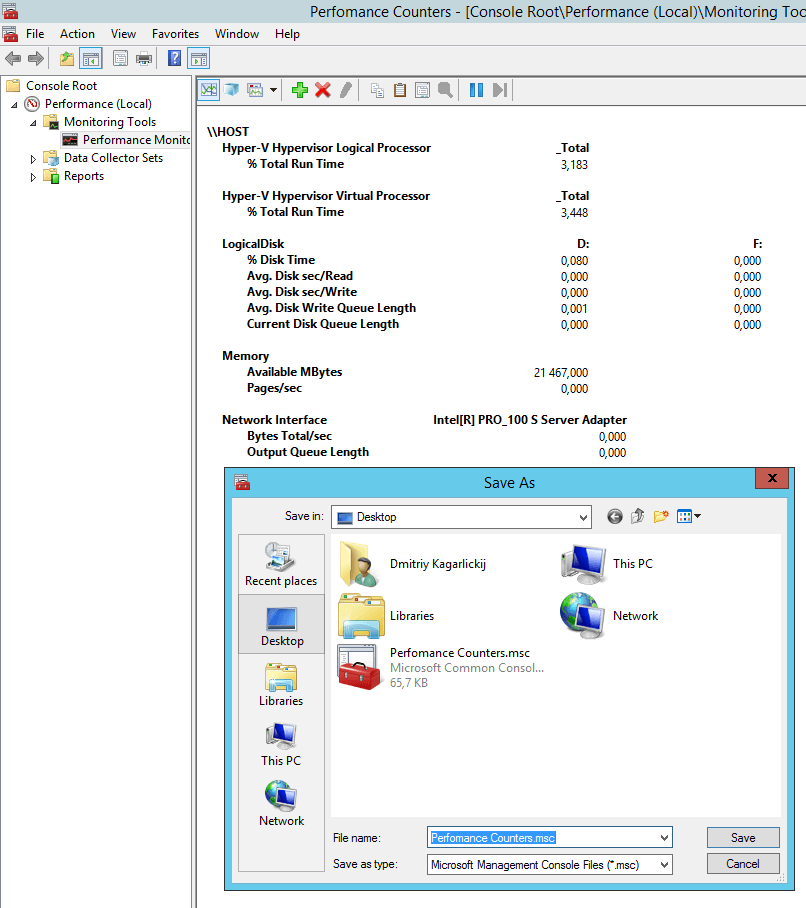
Аналогичные (за исключением CPU, он там с помощью Processor(*)% Processor Time меряется) счетчики можно настроить внутри виртуальных машин, с целью оценки базовых параметров производительности.
Оглавление цикла статей «Мониторинг производительности и статистика Hyper-V»


